
Behind the Scenes Lambda
🌇 Sunset
The sun is setting on these articles, they are still useful, but they are not the future. They are the past, and likely outdated. Read with caution.
Writing code and deploying it to AWS Lambda is as easy as baking a cake (depending on the type of cake). Lambda performs the heavy lifting for you, from provisioning to scaling. But where is the magic happening and how does it actually work under the hood? Lets find out together!
Lambda is split into a control plane and data plane. Each plane is responsible for a specific set of activities in the service. The Control Plane provides management APIs and manages integrations with all AWS services. Whilst the Data Plane is Lambda’s Invoke API that triggers Lambda function invocations, this explanation is still very abstract but things will become clearer over time.
Deployment Interoperability
When deploying your Lambda function, you can either define a container image which is stored in Amazon ECR registry or deploy the code through a .zip file. You can specificy the location of an object in Amazon S3 by defining this in a CloudFormation template or through the CLI. If you’re uploading the .zip through the console, it will be stored in an inaccessible S3 bucket.
Function code which is uploaded using the ZIP format is optimized once, and then is stored in an encrypted format using an AWS-managed key and AES-GCM. Functions uploaded to Lambda using the container image format are also optimized. Your idle Lambda function is actually just stored as a .zip file residing in Amazon S3.
The container image is downloaded from its original source, optimized into chunks, and then stored as encrypted chunks using an encryption method which uses a combination of AES-CTR, AES-GCM, and a SHA-256 MAC. The encryption method allows Lambda to securely deduplicate encrypted chunks.
Breaking down the architecture
Lambda creates the Execution environment (worker) on a fleet of EC2 instances. These workers are bare metal Nitro instances which are launched in a seperate inaccessible AWS account. These workers have hardware-virtualized MVMs (Micro Virtual Machines) created by Firecracker1 (Linux’s Kernel-based Virtual Machine). Workers have a lease lifetime of 14 hours, when a worker approaches this maximum, no further invocations are forwarded to the worker and the worker is terminated. Each worker has the ability to host one concurrent invocation, but is being reused if multiple invocations of the same function occur. Lambda never reuses an execution environment across multiple functions.
All communication between workers is encrypted using AES with Galois. Customers cannot directly interact with a worker as it’s hosted in a network isolated VPC in the Lambda AWS service accounts.
Load Balancing/Scaling
Lambda intentionally concentrates the load on the smallest possible busy sandboxes2. As a sandbox is busy in a very binary way (either it’s invoked or it’s idle). So just by counting the sandboxes that are currently busy you can get a very clear picture of what kind of load is on the system. Lambda takes advantage of statistical multiplexing by copying very different kind of workloads onto the same server opposed to copying the same workload on the server (if you copy a function its workload and make it run ‘concurrently’, it’s high likely possible that if one spikes in CPU usage another one will do too). The more uncorrelated workloads you put on a machine, the better they behave in aggregate (flat out the spikes). Because AWS opperates at such immense scale they are able to find these uncorrelated workloads, you can obviously not do this on a low scale computing platform. To summarize it, AWS picks uncorrelated workloads that pack together well.
Worker layers
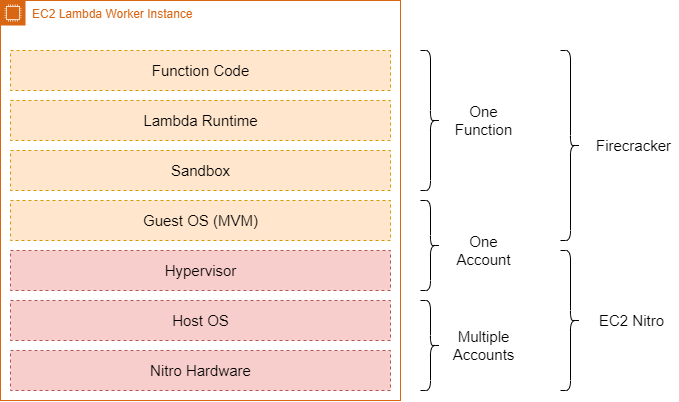
The machines that we run our workloads on are called Workers, these are cut-up by Firecracker (which we’ll dive into later on) to result into multiple isolated environments. The function code is your code which is provisioned by the Worker Manager to download and initialize your Lambda package on the Worker. The Lambda runtimes are built-in runtimes that Lambda supports, such as: .NET Core, NodeJs, Python, etc. The contents of the sandbox is a Linux guest kernel (AWS stripped off most kernels features). The next layer is the guest-OS (Amazon Linux 2), AWS runs multiple Amazon Linux distributions on a Worker (reaching from hundreds to thousands) isolated from eachother by virtualization using the Linux KVM feature. The bottom two layers are bound to the actual instance, which is the host-OS and the provisioned hardware.
The guest-OS layer is bound to a single AWS account, multiple functions can run on this same guest-OS. The boundary that’s put between accounts is virtualization, due to security reasons. Underneath the sandbox layer is the same kind of technology that powers containerization. As you might know; containers do not really exist, they are rather isolated through a set of tools that the Linux Kernel provides us. Lambda makes use of these tools, such as cgroups which allows us to for example set apart the maximum memory footprint of a function. Seccomp: which is sort of a firewall for the Linux Kernel, for example to restrict a syscall from passing in only a set of arguments opposed to all available arguments within the syscall. Lambda restricts the isolated environment from performing any additional syscalls through Seccomp besides to what it’s supposed to be doing.
Synchronous Execution Path
Synchronous invocations are typically referred to as invocations that are returning a result to a client that’s awaiting this result. This might be something as simple as invoking one function that computes something and then using the result in another function.
Lambda evaluates every request through an internal Application Load Balancer to manage and balance the requests against the underlying infrastructure, the load balancer forwards the request to a Frontend Worker which in return will authenticate the caller and check function metadata to validate if the per function concurrency hasn’t been exceeded. Assuming this went ok, the Frontend Worker will route to a Worker Manager. The Worker Manager is responsible for tracking warm Lambda Sandboxes which are ready for invocation. Note, as your functions concurrency scales up also the amount of Worker Managers scales up, and thereby also more Workers are scaled up.
If it’s a first-time (cold-start) synchronous invocation there’s no available sandbox ready for invocation. The Worker Manager communicates with a Placement Service which is responsible to place a workload on a location for the given host (it’s provisioning the sandbox) and returns that to the Worker Manager. The Worker Manager can then call Init to initialize the function for execution by downloading the Lambda package from S3 and setting up the Lambda runtime. The Frontend Worker is now able to call Invoke.
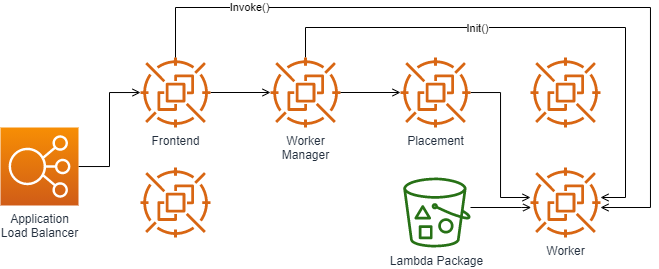
The Placement Service places sandboxes on Workers to maximize packing density without impacting cold-path latency.
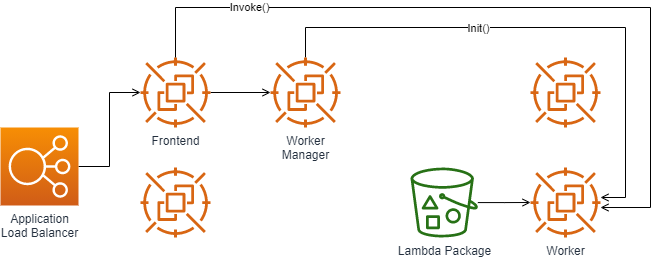
On a warm-start (majority of invocations), the Worker Manager is aware of a readily available warm sandbox to invoke. As you can see the execution path is now shorter due to taking out the Placement service. Most of the time your Lambda function will be following this execution path as warm-paths are the prefered call pattern.
Asynchronous/Events Execution Path
Asynchronous invocations and events are executed through a path that’s a bit different than synchronous invocations. We’ll go over how Asynchronous/Event invocations are executed and how stream execution paths are laid out.
The Application Load Balancer forwards the invocation to an available Frontend which places the event onto an internal queue, there’s a set of pollers assigned to this internal queue which are responsible for polling it and moving the event onto a Frontend synchronously. After it’s been placed onto the Frontend it follows the synchronous invocation call pattern which we covered earlier.
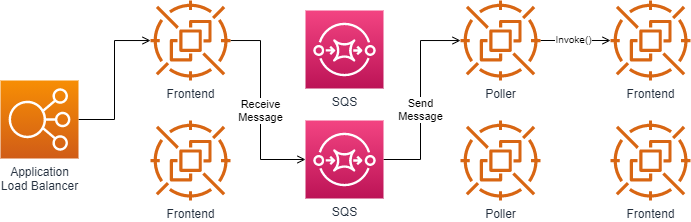
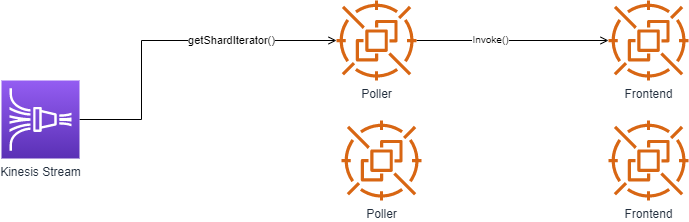
How are stream sources like Kinesis or DynamoDB processed? When an application puts a record into Kinesis an event is fired off which will notify Lambda. The assigned pollers will receive the message from Kinesis and place the messages onto the Frontend synchronously, Lambda will then follow with our already covered synchronous execution path.
Firecracker
Firecracker is AWS their open source virtual machine monitor which you can find on Github. Firecracker is responsible for providing the isolation between Lambda functions that run on top of the EC2 Nitro hardware we spoke about earlier. Think of each Lambda function having it’s own server, sounds wasteful right? Placing multiple workloads on the same server in each their own isolated environment sounds more efficient. As modern servers have over TBs of memory and hundreds of cores, AWS decided to cut these servers up through virtualization.
According to Jeff Barr: We used per-customer EC2 instances to provide strong security and isolation between customers. As Lambda grew, we saw the need for technology to provide a highly secure, flexible, and efficient runtime environment for services like Lambda and Fargate. Using our experience building isolated EC2 instances with hardware virtualization technology, we started an effort to build a VMM that was tailored to integrate with container ecosystems.
I came across the above earlier during my research phase, nice to look back at compared to where Lambda stands now. Anyways, lets dive into the core of Firecracker and some diagrams.
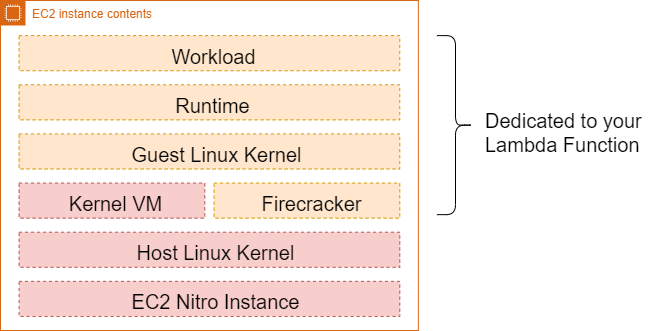
Your Lambda function has some dedicated components which are reserved for just one concurrent invocation, see the preceding image. Firecracker is a very lightweight process so there’s not too much overhead to initialize this setup on a server. Firecracker provides the isolation by working with KVM (which is a Linux Feature that lets you turn your Linux into a hypervisor that allows a host machine to run multiple, isolated virtual environments called guests or virtual machines (VMs)). KVM is responsible for interacting with the host OS to do secure hardware virtualization, perform memory management and abstract the hardware details.
If KMV does so much of the heavy lifting than what is Firecracker actually doing for us? Firecracker its job is to configure the KVM, it uses the KVM API to create and manage MVMs. Firecracker takes care of device emulation, we earlier mentioned that AWS runs thousands of workloads on the same server but obviously the machine does not have thousands of CPUs and thousands of SSDs, so how does Firecracker perform device emulation? It pretends to be hardware to the MVMs whilst abstracting the host’s hardware by cutting it up. Firecracker also primarily acts as a monitor as one MVM’s performance should not affect another MVM’s performance, under the hood its still just 1 machine. Every function runs in a seperate Firecracker process in the host OS. Firecracker is especially built for serverless, it has a small memory footprint and can boot a Linux MVM in sub 125ms and a microkernel in sub 7ms.
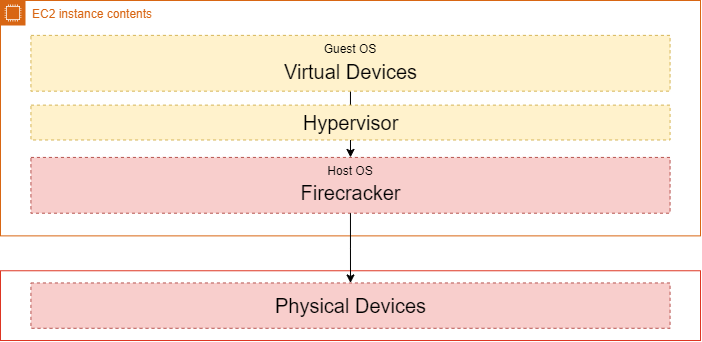
As we mentioned earlier, every function is driven by its own Firecracker process, these processes actually share a bit of memory through virtio. Virtio with some additional dependencies inside the guest kernel pretends to the guest-OS to be any hardware device that the kernel is dependent on. Firecracker sits on the IO path, if you would want to write to disk from a Lambda function that call will be evaluated by the guest-OS which in return will pass it on to the virtio driver, the virtio driver will commit it to the shared memory area (ring buffer) and Firecracker will be notified to persist to the physical disk.
An interesting footnote to this section is that all vCPU threads are considered to run malicious code when they start. These vCPU threads are contained by trusted execution environments which are ordered from guest vCPU threads to host vCPU threads. Firecracker is wrapped in the jailer binary. The jailer binary initializes resources that require permissions and then executes into the Firecracker binary which is then ran as an unpriviliged process so it can only access specific resources.
Firecracker provides a REST API to manage MVMs, if you would like to take a look at the OpenAPI format click here.
Resources
- I’ve used both SRV409-R1 and SVS405-R1 as a reference to write this article.
- Marc Brooker (ex AWS Lambda Tech Lead) his article on Firecracker was a very interesting read.
- Lambda Executions under the Security Overview of AWS Lambda within the AWS Whitepaper section had some well detailed explanations.
You can mail me on ⟨bb@sembtrosagccae.hn⟩ for questions or feedback.